Identificar y Marcar Palabras Clave Duplicadas en Notepad++
Aprende a identificar y marcar palabras clave duplicadas en Notepad++ siguiendo esta guía paso a paso. Esta técnica es indispensable para optimizar sus estrategias de contenido y palabras clave.
El manejo efectivo de keywords duplicadas es crucial para la optimización de contenido. Notepad++ ofrece herramientas poderosas que facilitan esta tarea, mejorando significativamente tu eficiencia y precisión.
Pasos para Identificar Keywords Duplicadas
Identificar duplicados es sencillo con Notepad++, siguiendo estos pasos detallados.
te mostramos 2 formas.
La primera muy sencilla, pues es una opción del menú.
La segunda es para amantes del REGEX, pues para practicar formulas REGEX viene genial.
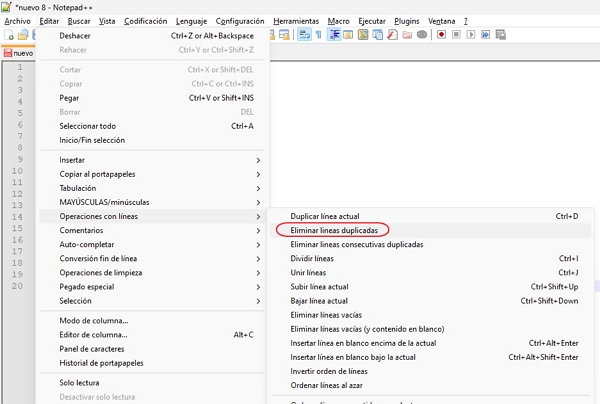
Identificar Keywords Duplicadas NOTEPAD++ desde el menú
Simplemente acceder a la opción del menú que facilta Notepad++ para eliminar duplicados
- Paso 1: Abrir Notepad++
- Paso 2: Ir al menúInsertar las Palabras Clave. Asegura que tu lista de palabras clave esté en el documento, una por línea.

Esto dejará la lista de keywords sin duplicados
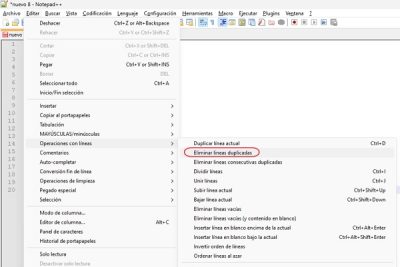
Identificar Keywords Duplicadas NOTEPAD++ con REGEX
- Paso 1: Abrir Notepad++. Inicio de Notepad++ en tu computadora.
- Paso 2: Insertar las Palabras Clave: Asegura que tu lista de palabras clave esté en el documento, una por línea.
- Paso 3: Ordenar la Lista. Ordena alfabéticamente para facilitar la identificación de duplicados. Esto se hace desde el menú Editar > Línea de Operaciones.
- Paso 4: Usar la Función de Búsqueda. Abre el cuadro de búsqueda con Ctrl+F y cambia a la pestaña "Marcar".
- Paso 5: Configurar la Búsqueda para Encontrar Duplicados.
Usa la expresión regular ^(.*)(\r?\n\1)+$ para identificar duplicados, asegurando seleccionar "Expresión regular".
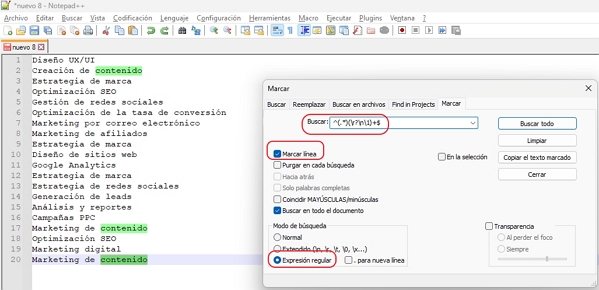
- Paso 6: Marcar los Duplicados. Con "Marcar Todo", Notepad++ resaltará los duplicados encontrados.
- Paso 7: Revisar y Eliminar Duplicados. Elimina manualmente los duplicados marcados para optimizar tu lista.
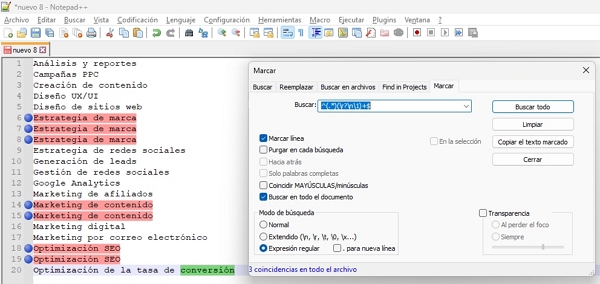
Explicación regex para eliminar duplicados
Contando que la lista está ordenada, la fórmula REGEX se compone de las siguentes partes:
La expresión regular ^(.*)(\r?\n\1)+$ es bastante útil para identificar líneas duplicadas consecutivas en un texto, y se puede desglosar en partes para entender cómo funciona:
^: Este es el ancla de inicio de línea. Indica que el patrón debe coincidir al principio de una línea en el texto. Esto asegura que el patrón de búsqueda se aplique a cada línea de forma individual.(.*): Este es un grupo de captura que coincide con cualquier carácter (el punto.significa "cualquier carácter excepto el salto de línea") cero o más veces (el asterisco*significa "cero o más veces"). Este grupo captura el contenido completo de una línea.(.*): Captura la línea completa, lo que permite referenciar esta captura más adelante en la expresión regular.(\r?\n): Este es otro grupo de captura que coincide con un salto de línea. El\r?significa que el retorno de carro (CR,\r) es opcional, seguido de un avance de línea (LF,\n). Esto permite que la expresión regular funcione tanto en archivos de texto Unix/Linux (que usan\npara los saltos de línea) como en archivos de texto Windows (que usan\r\n).\1: Esto es una referencia hacia atrás al primer grupo de captura(.*).Permite buscar una línea que sea exactamente igual a la capturada por el primer grupo de captura. Esto es crucial para identificar duplicados, ya que busca coincidencias exactas del texto de la línea previamente capturada.+: Este cuantificador significa "una o más veces". Aplicado a(\r?\n\1), indica que la expresión regular busca una o más repeticiones consecutivas de la línea capturada por el primer grupo de captura, seguida por el patrón de salto de línea correspondiente.$: Este es el ancla de fin de línea. Asegura que el patrón coincida hasta el final de la línea.
En resumen, la expresión regular ^(.*)(\r?\n\1)+$ busca cualquier línea (^(.*)) seguida por una o más repeticiones de sí misma ((\r?\n\1)+), donde \1 se refiere a la misma línea capturada inicialmente. El uso de ^ y $ asegura que la búsqueda se realice en el contexto de líneas completas, desde el inicio hasta el final de cada línea, permitiendo así identificar líneas duplicadas consecutivas en un texto.
Para ver más expresiones regex puedes ver nuestro post de Expresiones regulares en PHP regex.
Deja una respuesta